跟着简叔学的,可以B站搜索 简说linux
进程虚拟地址空间的管理机制
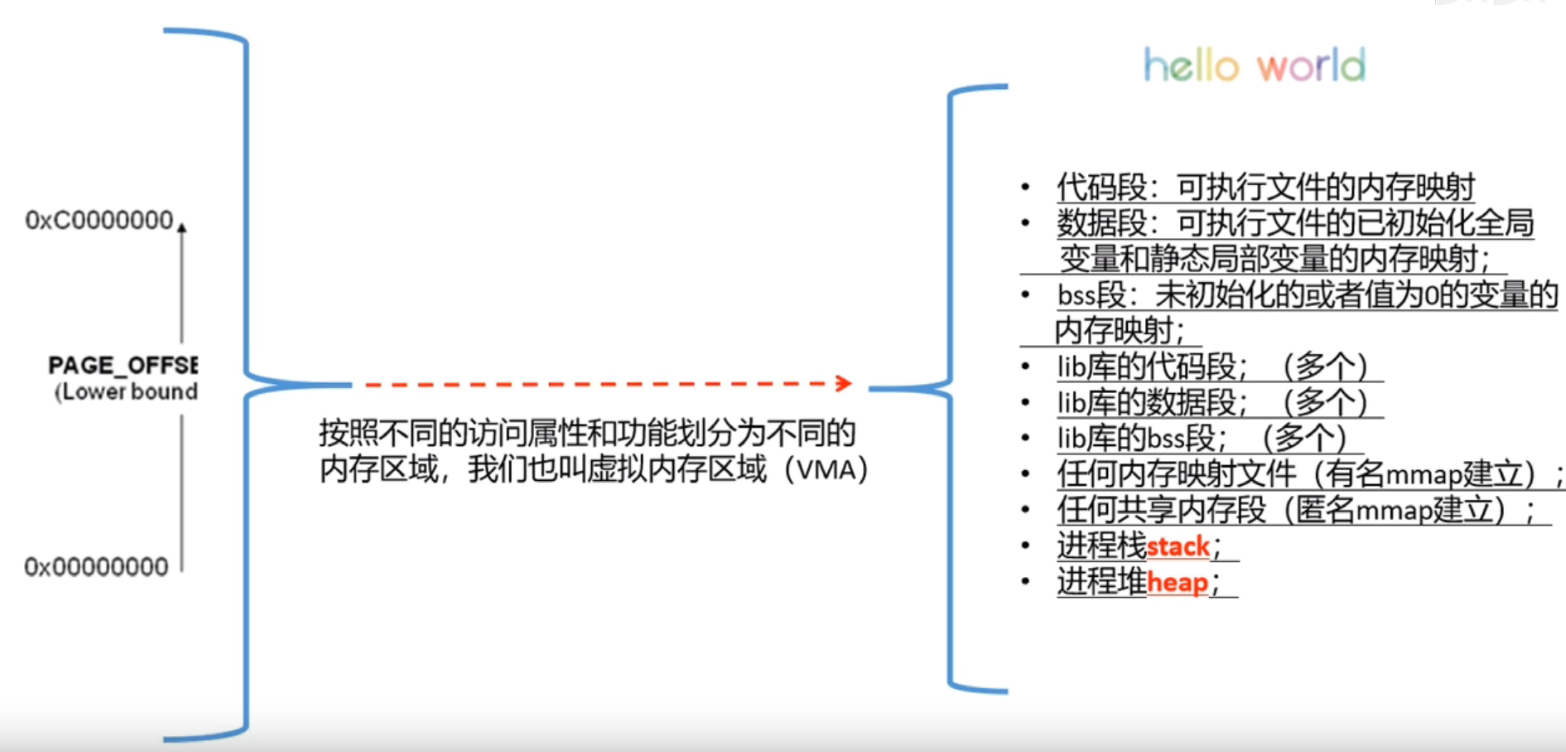
什么是虚拟地址空间
内存的页表映射机制实现虚拟地址到物理地址的转换。内核只需维护一个页目录表,而多个进程共享用户空间是不安全的,需要做管理,不然用户空间太大,若每个进程也只维护一个页目录表的话,查找管理不便。那么虚拟地址空间的管理机制是什么样的呢。
在linux中,proc是一个虚拟文件系统,也是一个控制中心,里面储存是当前内核运行状态的一系列特殊文件;该系统只存在内存当中,以文件系统的方式为访问系统内核数据的操作提供接口,可以通过更改其中的某些文件来改变内核运行状态。
写一个最简单的c语言程序并运行
!
使用top命令查看进程的ID,

使用cat /proc/232759/maps可以查看进程的虚拟地址空间的信息
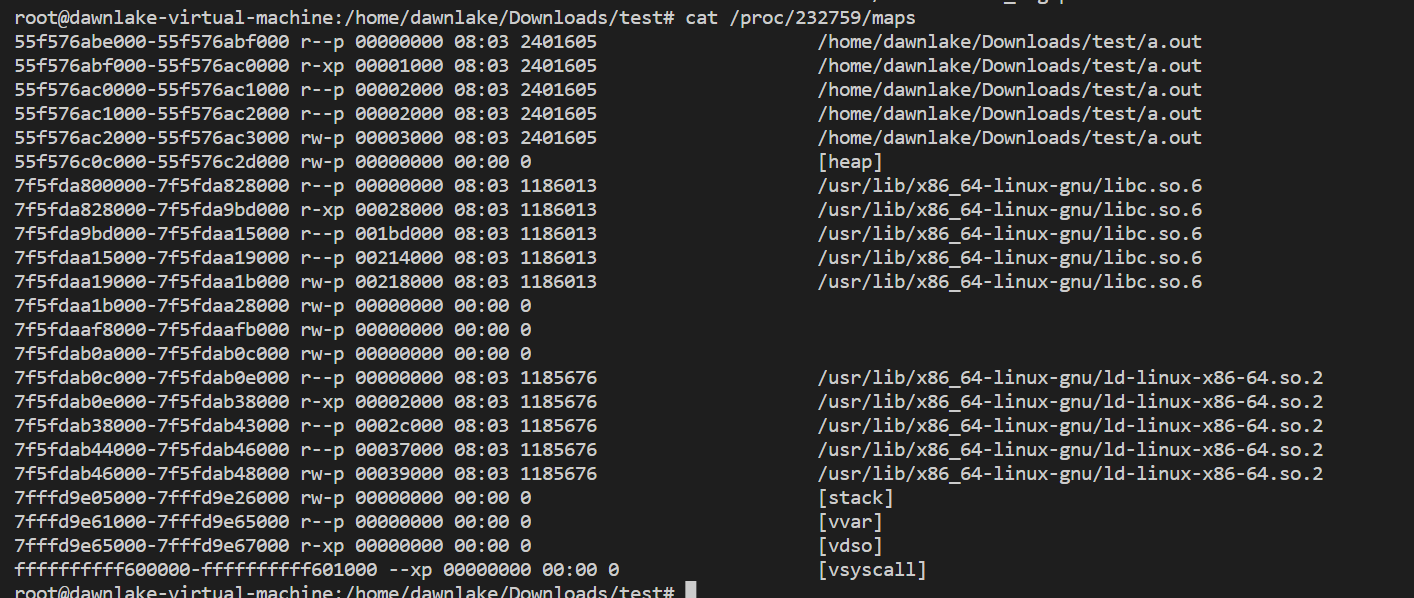
含义:

虚拟地址空间的管理
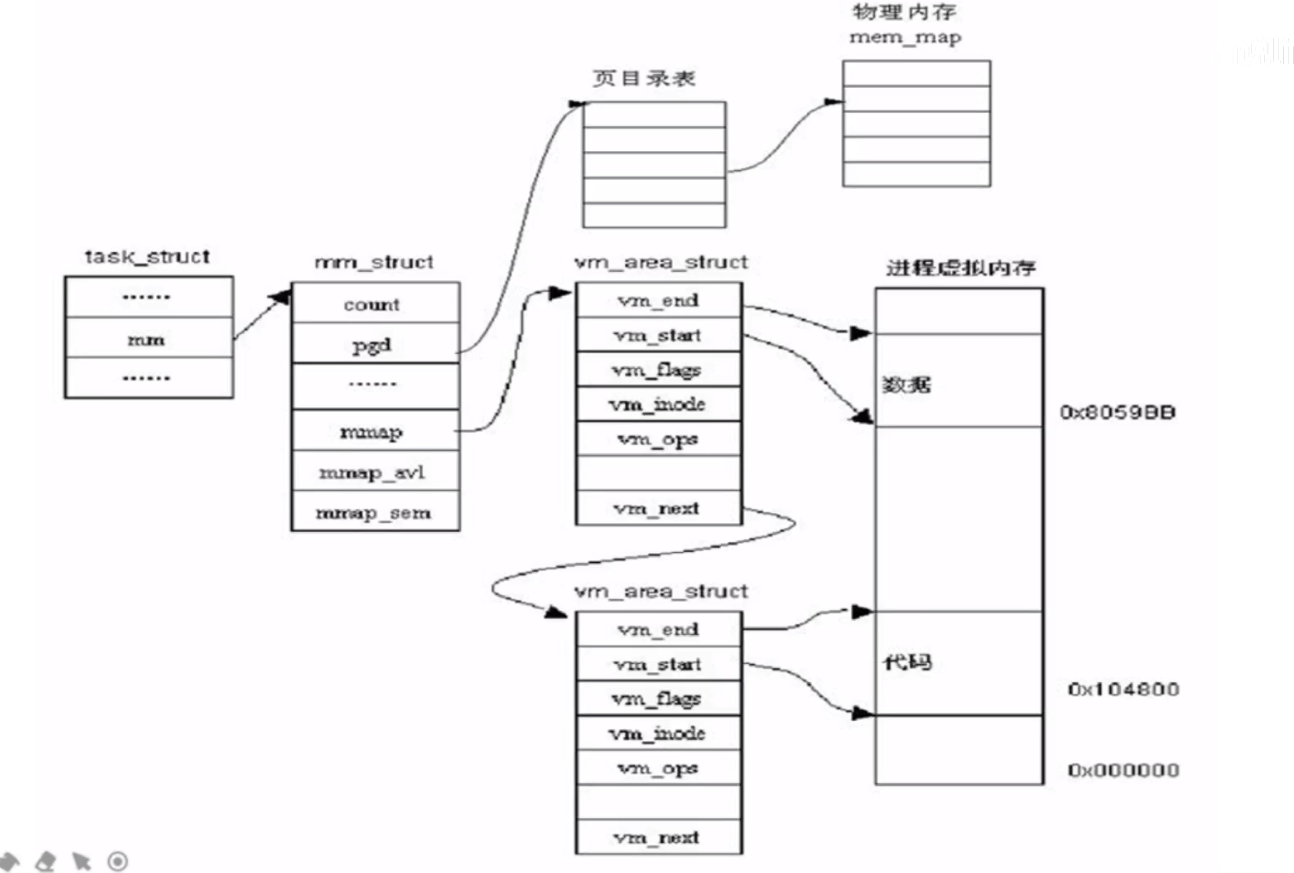
内核使用下面的数据结构来描述一个进程的的虚拟地址空间,文件路径/include/linux/mm_types.h,其中第一个成员 vm_area_struct被用来描述一个虚拟内存区域(VMA),一个地址空间由多个虚拟内存区域,可以看到是一个链表的形式。pgd_t * pgd 指向页目录表,地址映射必备,如果两个进程有同一个页目录表,那这两个进程甚至可以当成线程使用。
1 | struct mm_struct { |
那我们再来看看虚拟内存区域的(VMA)这个结构,内核将每个内存区域当作一个单独的内存对象管理,因此我们程序的代码段、数据段、未初始化全局变量、堆栈这种都有自己的 vm_area_struct然后再由虚拟地址空间把这些 vm_area_struct给串起来。
这里面 有一个mm_struct指针 而mm_struct又与tast_struct有一一的对应关系,因此就可以知道这块虚拟内存区域属于的哪一个进程。
1 | /* |
下面这个图太牛了
使用以下函数可以把文件映射到进程的地址空间里,具体就是再给这个进程分配一个VMA并把这个东西加到mm_struct里边
1 |
|
在linux中,如果clone()时设置CLONE_VM标志,我们把这样的进程称作为线程。线程之间共享同样的虚拟内存空间。fork()函数利用copy_mm()函数复制父进程的mm_struct,也就是current->mm域给其子进程。(/kernel/fork.c) 参数中的struct task_struct *tsk是子进程的task struct
1 |
|
用户空间的mmap函数在内核中的实现
用户空间使用mmap函数可以将一个文件或者设备映射到进程的地址空间去,上面说的,创建一个VMA加进去,到底是不是这样呢?映射的作用是,这样读写文件会快,如果不这么做的话,还会有用户空间和内核空间的数据拷贝过程,数据多的时候会极大影响性能。
用户空间的mmap()会通过系统调用调用到内核的do_mmap()函数。
do_mmap()函数会:
1.首先创建一个新的VMA并初始化,然后加入进程的虚拟地址空间里。
2.然后调用底层的mmap函数建立VMA和实际物理地址的联系(建立页表) 底层的mmap会根据文件类型不同有差异化。
驱动的mmap实现
设备驱动的mmap实现主要是将这个物理设备的可操作区域映射到一个进程的虚拟地址空间。这样用户空间就可以直接采用指针的方式访问设备的可操作区域。在驱动中的mmap实现主要是完成一件事,就是建立设备的可操作区域到进程虚拟空间地址的映射过程。同时也需要保证这段映射的虚拟存储器区域不会被进程当做一般的空间使用,因此需要添加一系列的保护方式。
驱动的mmap建立虚拟地址和物理地址的映射
1 | //建立vma和物理地址的映射的工作由remap_pfn_range来完成,原型如下: |
我们可以重新回去看看file_operation这个结构体,这个就代表这驱动提供的能力,也就是要让驱动有mmap的能力,就需要实现 int(*mmap)函数,建立file 与 VMA的映射。就是用上面 的函数
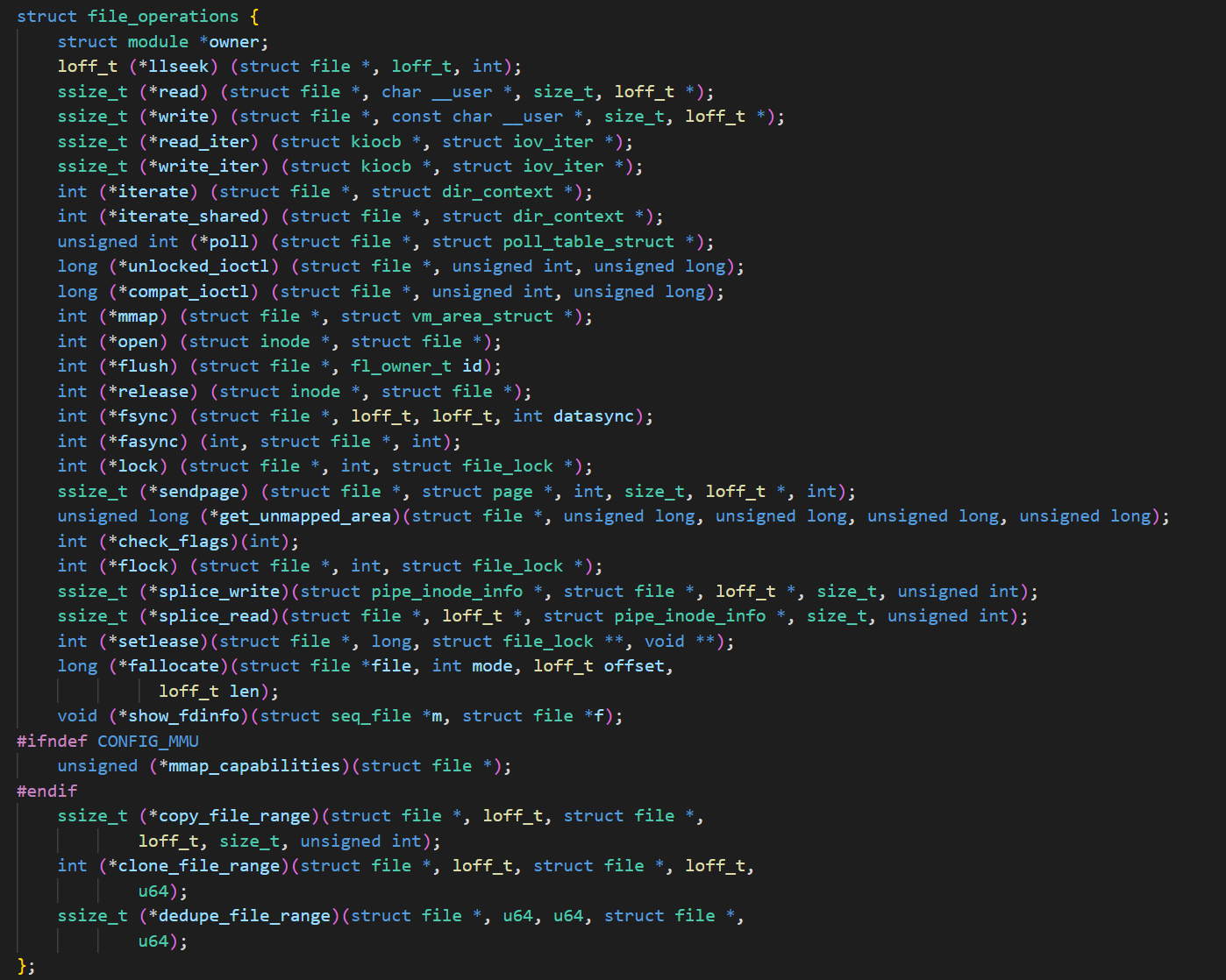
1 | int (*mmap) (struct file *, struct vm_area_struct *); |
因此mmap是一种零拷贝技术。
进程的用户栈和内核栈
- 用户栈:
基于进程的虚拟地址空间的管理机制实现;以VMA的形式实现; - 内核栈:
每个进程都有属于自己的独自的内核栈;
大小根据不同的体系结构而不同,一般为1个page,也就是4K;
linux内核中进程的描述方式
/include/linux/sched.h 有点长 不忘往这里放了吧 一个struct 四五百行,,,描述了linux进程的通用部分。然后它里面有一个成员结构体是,thread_info 描述了特定体系结构的汇编代码段需要访问的那部分数据。
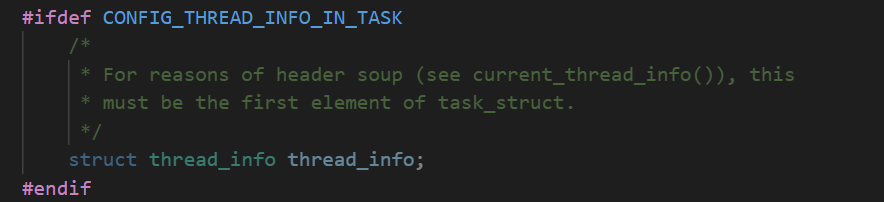
内核栈定义如下:
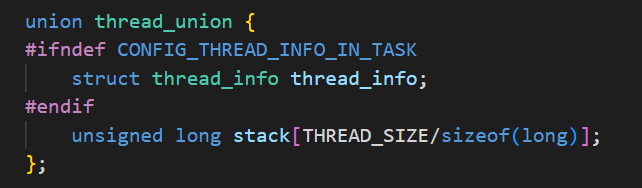
thread_info包含了 自身体系架构的一些属性,不同体系有差异所以要单独实现,比如下面是arm的。
arch/arm/include/asm/thread_info.h
1 | struct thread_info { |