感觉不了解一下NVMe,Femu的代码阅读起来还想确实有点困难。使用FEMU模拟NVMe设备,是需要了解这个协议的。完全参考蛋蛋读NVMe,讲的十分清晰。
1.host 如何使用 NVMe协议与SSD通信
PCIe(Peripheral Component Interconnect Express)是一种高速串行总线标准,用于连接计算机内部的各种硬件设备。下图为PCIe系统的简单架构图,图中的NVMe Subsystem一般就是SSD。SSD作为一个PCIe Endpoint通过PCIe连着Root Complex (RC), 然后RC连接着CPU和内存。Root Complex是PCIe系统中引入的概念,它将CPU、内存子系统和PCIe子系连接起来。Root Complex是PCIe总线的根节点,将PCIe设备与CPU/Memory连接到一起,与其余PCIe设备(包括Switch)连接的端口称为RootPort。
”我们可以认为RC就是CPU的代言人,助理,或者小蜜。作为系统中最高层,CPU说:我很忙的,你SSD有什么事情先跟我小蜜说!尽管如此,SSD的地位还是较过去提升了一级,过去SSD别说直接接触霸道总裁,就是连小蜜的面都见不到,SSD和小蜜之间还隔着一座南桥呢。滚蛋吧,南桥君!“——蛋蛋
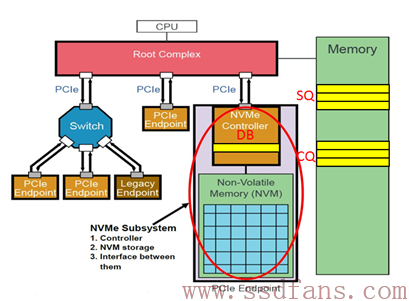
NVMe有两种命令,一种叫Admin Command,用以Host管理和控制SSD;另外一种就是I/O Command,用以Host和SSD之间数据的传输。
有了这两种命令还需要,通信的重要三个组件:Submission Queue (SQ),Completion Queue(CQ)和Doorbell Register (DB)。 SQ和CQ位于Host的内存中,DB则位于SSD的控制器内部。
当Host要发送命令时,先把准备好的命令放在SQ中,然后通知SSD来取;通知的方式就是,通过SSD端的DB寄存器,通知SSD可以来取命令;CQ也是位于Host内存中,一个命令执行完成,成功或失败,SSD总会往CQ中写入命令完成状态。
总结步骤:

- Host写命令到内存中的SQ;
- Host写SSD控制器的DB,通知SSD取指;
- SSD控制器收到通知,于是从内存中的SQ取指;
- SSD控制器执行指令;
- 指令执行完成,SSD控制器往内存中的CQ写指令执行结果;
- 然后SSD控制器产生MSI中断通知Host指令完成;
- Host收到MSI中断,处理CQ,查看指令完成状态;
- Host处理完CQ中的指令执行结果,通过DB回复SSD:指令执行结果已处理!
2. SQ,CQ和DB 详解

SQ与CQ并不一定是一对一的关系。而之前说的NVMe有两种命令,从而也有两种SQ与CQ。一种是Admin,另外一种是I/O,前者放Admin命令,用以Host管理控制SSD,后者放置I/O命令,用以Host与SSD之间传输数据,不可以混着放。系统中只有一对Admin SQ/CQ,I/O SQ/CQ却可以很多,多达65535(64K减去一个SQ/CQ)。Host端每个Core可以有一个或者多个SQ,但只有一个CQ。设置多个core可以利用多线程满足性能需求,一个线程独享一个SQ,且可以为SQ设置不同的优先级,重要的SQ指令优先被执行。
实际系统中用多少个SQ,取决于系统配置和性能需求,可灵活设置I/O SQ个数。
作为队列,每个SQ和CQ都有一定的深度:对Admin SQ/CQ来说,其深度可以是2-4096(4K);对I/O SQ/CQ,深度可以是2-65536(64K)。队列深度也是可以配置的。 这也是NVMe相较与其他协议更屌的地方。AHCI只有一个命令队列,且队列深度是固定的32。
还有重要的一点:每个SQ放入的是命令条目,无论是Admin还是I/O命令,每个命令条目大小都是64字节;每个CQ放入的是命令完成状态信息条目,每个条目大小是16字节。
再进行一波小总结:
SQ用以Host发命令,CQ用以SSD回命令完成状态
SQ/CQ可以在Host的内存中,也可以在SSD中,但一般在Host 内存中(所有系列文章都是基于SQ/CQ在Host内存中讲的);
两种类型的SQ/CQ:Admin和I/O,前者发送Admin命令,后者发送I/O命令;
系统中只能有一对Admin SQ/CQ,但可以有很多对I/O SQ/CQ;
I/O SQ与CQ可以是一对一的关系,也可以是一对多的关系;
I/O SQ是可以赋予不同优先级的;
I/O SQ/CQ深度可达64K,Admin SQ/CQ深达4K;
I/O SQ/CQ的广度和深度都可以灵活配置;
每条命令大小是64字节,每条命令完成状态是16字节;
SQ与CQ都是是环形队列,DB而就是用来记录一个SQ或者CQ的Head和Tail。每个SQ或者CQ,都有两个对应的DB: Head DB和Tail DB。DB是在SSD端的寄存器,记录SQ和CQ的头和尾的位置。这样SQ头尾之间的就是待处理的命令,SSD通过该SQ的两个DB获取这个信息。Host存放命令到SQ后就会更新SSD端的DB寄存器。 SSD controller 把这三个指令取到之后,会更新DB。
同样的,当 SSD执行完命令,会将消息放入CQ,并更新CQ尾的DB寄存器,然后通过MSI中断通知host已经执行完host的命令了。host取出CQ中的完成信息进行处理,并更新CQ的头。生产者修改尾,消费者修改头。
细细琢磨可能发现一些小漏洞,Host只能写DB,而不能读DB,且只能写SQ尾和写CQ头。那它如何知晓SQ头与CQ尾。Host发了取指通知后,它并不清楚SSD什么时候去取命令,取了多少命令。答:SSD往CQ中写入命令状态信息,就包含了这几条。
小总结:
- DB在SSD Controller端,是寄存器
- DB记录着SQ和CQ的Head和Tail
- 每个SQ或者CQ有两个DB: Head DB 和Tail DB
- Host只能写DB,不能读DB
- Host通过SSD往CQ中写入的命令完成状态获取Head或者Tail
3.数据怎么传递的
数据传递无非两种方向,host内存 <==> SSD。
F.png)
Host如果想往SSD上写入用户数据,需要告诉SSD写入什么数据,写入多少数据,以及数据源在内存中的什么位置,这些信息包含在Host向SSD发送的Write命令中。每笔用户数据对应着一个叫做LBA(Logical Block Address)的东西,Write命令通过指定LBA来告诉SSD写入的是什么数据。对NVMe/PCIe来说,SSD收到Write命令后,通过PCIe去Host的内存数据所在位置读取数据,然后把这些数据写入到闪存中,同时得到LBA与闪存位置的映射关系。
Host如果想读取SSD上的用户数据,同样需要告诉SSD需要什么数据,需要多少数据,以及数据最后需要放到Host内存的哪个位置上去,这些信息包含在Host向SSD发送的Read命令中。SSD根据LBA,查找映射表,找到对应闪存物理位置,然后读取闪存获得数据。数据从闪存读上来以后,对NVMe/PCIe来说,SSD会通过PCIe把数据写入到Host指定的内存中。这样就完成了Host对SSD的读访问。(SSD的映射表是用来记录逻辑块地址(LBA)和物理块地址(PBA)之间的对应关系的,它是SSD固件的核心部分。SSD工作时,它的绝大部分映射表是存储在FLASH里面,还有一部分存储在片上RAM上。这样做的目的是为了提高性能和减少对FLASH的磨损。当SSD断电时,会把映射表写回到FLASH中,以防止数据丢失。)
再说明一下 Root Complex是PCIe总线系统中的一个概念,它将CPU、内存子系统和PCIe子系连接起来。它负责将CPU的访问事务转换为PCIe总线上的访问事务,同时也要解析下游PCIe设备上报的报文,并根据报文内容,将信息或者数据通知CPU。内存和SSD的数据交换需要通过Root Complex作为桥梁,因为Root Complex可以将存储域地址空间转换为PCIe域地址空间。
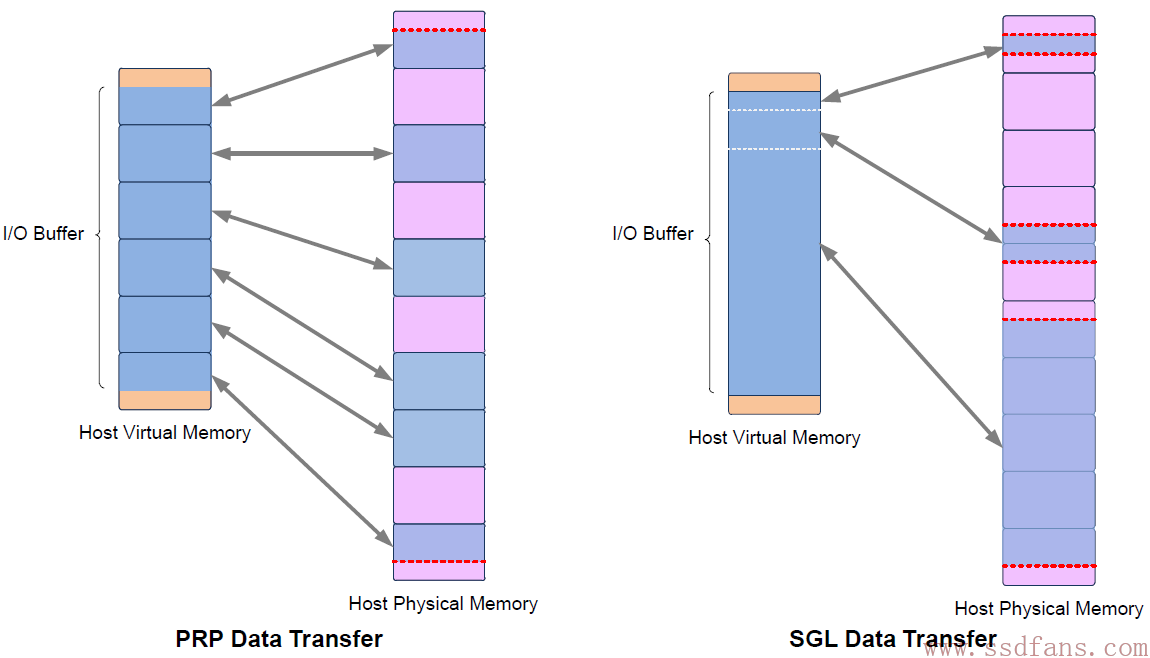
无论是写入还是读取,Host都是发送命令的一方,并不负责数据的主动传输。其中Host关注的是逻辑地址,SSD需要通过逻辑地址找到真正的数据存放位置。Host也有两种方式来告诉SSD数据所在内存位置,一是PRP (Physical Region Page ),二是SGL (Scatter/Gather )。
3.1 PRP (Physical Region Page)
NVMe把Host的内存划分为一个一个页(Page),页的大小可以是4KB,8KB,16KB… 128MB。好像一般都是4KB。

PRP Entry本质就是一个64位内存物理地址,只不过把这个物理地址分成两部分:页起始地址和页内偏移。最后两bit是0,说明PRP表示的物理地址只能四字节对齐访问。页内偏移可以是0,也可以是个非零的值。
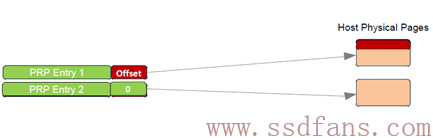
PRP Entry描述的是一段连续的物理内存的起始地址。如果需要描述若干个不连续的物理内存呢?那就需要若干个PRP Entry。把若干个PRP Entry链接起来,就成了PRP List。
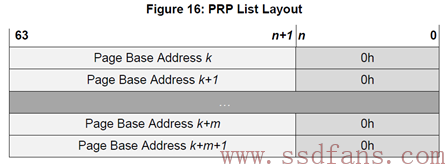
PRP List中的每个PRP Entry的偏移量都必须是0,PRP List中的每个PRP Entry都是描述一个物理页。它们不允许有相同的物理页,不然SSD往同一个物理页写入几次的数据,导致先写入的数据被覆盖。
每个NVMe命令中有两个域:PRP1和PRP2,Host就是通过这两个域告诉SSD数据在内存中的位置或者数据需要写入的地址。

PRP1和PRP2有可能指向数据所在位置,也可能指向PRP List。类似C语言中的指针概念,PRP1和PRP2可能是指针,也可能是指针的指针,还有可能是指针的指针的指针。根据不同的命令,SSD总能一层一层的剥下包装,找到数据在内存的真正物理地址。(个人理解应该是多级页表类似的东西)
下面是一个PRP1指向PRP List的示例:
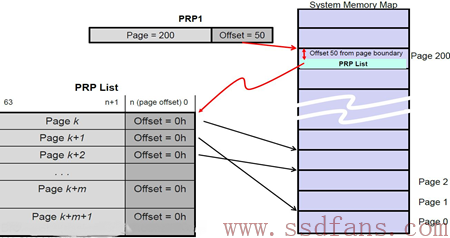
PRP1指向一个PRP List,PRP List位于Page 200,页内偏移50的位置。SSD确定PRP1是个指向PRP List的指针后,就会去Host内存中(Page 200,Offset 50)把PRP List取过来。获得PRP List后,就获得数据的真正物理地址,SSD然后就会往这些物理地址读入或者写入数据。
3.2 SGL (Scatter/Gather )
对Admin命令来说,它只用PRP告诉SSD内存物理地址;对I/O 命令来说,除了用PRP,Host还可以用SGL的方式来告诉SSD数据在内存中写入或者读取的物理地址。
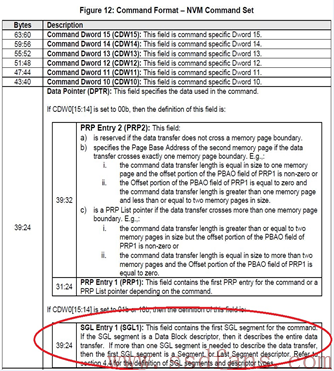
Host在命令中会告诉SSD采用何种方式。具体来说,如果命令当中DW0[15:14]是0,就是PRP的方式,否则就是SGL的方式。
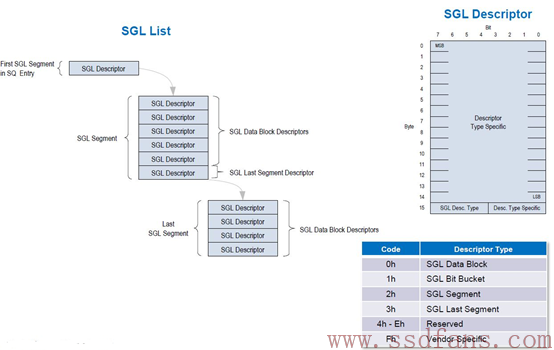
SGL是一个数据结构,用以描述一段数据空间,这个空间可以是数据源所在的空间,也可以是数据目标空间。SGL(Scatter Gather List)首先是个List,是个链表,由一个或者多个SGL Segment组成,而每个SGL Segment又由一个或者多个SGL Descriptor组成。SGL Descriptor是SGL最基本的单元,它描述了一段连续的物理内存空间:起始地址+空间大小。
每个SGL Descriptor大小是16字节。一块内存空间,可以用来放用户数据,也可以用来放SGL Segment,根据这段空间的不同用途,SGL Descriptor也分几种类型。

有4种SGL Descriptor,一种是Data Block,这个好理解,就是描述的这段空间是用户数据空间;一种是Segment描述符。SGL是由SGL Segment组成的链表。既然是链表,前面一个Segment就需要有个指针指向下一个Segment,这个指针就是SGL Segment描述符,它描述的是它下个Segment所在的空间。特别地,对链表当中倒数第二个Segment,它的SGL Segment描述符我们把它叫做SGL Last Segment描述符。它本质还是SGL Segment描述符,描述的还是SGL Segment所在的空间。为什么需要把倒数第二个SGL Segment描述符单独的定义成一种类型呢?我认为是让SSD在解析SGL的时候,碰到SGL Last Segment描述符,就知道链表快到头了,后面只有一个Segement了;最后一种,SGL Bit Bucket,它只对Host读有用,用以告诉SSD,你往这个内存写入的东西我是不要的。好吧,不要,就不传了。
 |
 |
|---|---|
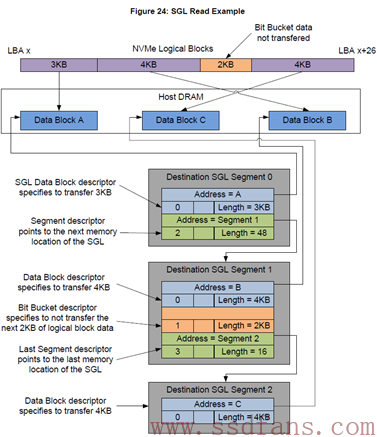
假设Host需要往SSD中读取13KB的数据,其中真正只需要11KB数据,这11KB的数据需要放到3个大小不同的内存中,分别是:3KB,4KB和4KB。
PRP与SGL的区别是:一段数据空间,对PRP来说,它只能映射到一个个物理页,而对SGL来说,它可以映射到任意大小的连续物理空间。有点像内存管理的分页与分段,果然计算机思想到哪都能用。
4.NVMe与PCIe传输层交互
来源:蛋蛋读NVMe之四 (ssdfans.com)这部分感觉对个人研究意义不大 所以就直接搬运了。方便以后看
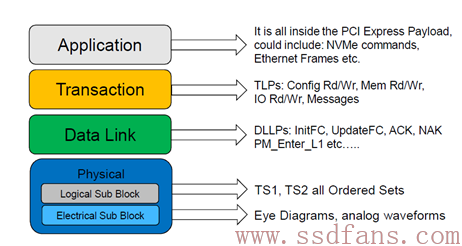
任何一种计算机协议,它都是采用这种分层结构的。下层总是为上层服务的。有些协议,上图所有的层次都有定义和实现,而有些协议,只定义了其中的几层。然而,要让一种协议能工作,它需要一个完整的协议栈,PCIe定义了下三层,NVMe定义了最上层,两者一拍即合,构成一个完整的Host与SSD通讯的协议。
PCIe与NVMe最直接接触的是传输层。在NVMe层,我们能看到的是64字节的命令,16字节的命令返回状态,以及跟命令相关的数据。而在PCIe的传输层,我们能看到的是TLP (Transaction Layer Packet)。还是跟快递做类比,你要寄东西,可能是手机,可能是电脑,不管是什么,你交给快递小哥,他总是把你要寄的东西打包,快递员看到的就是包裹,他根本不关心你里面的内容。PCIe传输层作为NVMe最直接的服务者,不管你NVMe发给我的是命令,还是命令状态,还是用户数据,我统统帮你放进包裹,打包后交给下一层,让数据链路层继续处理。
PCIe传输层传输的是TLP,它就是个包裹,一般由包头和数据组成,当然也有可能只有包头没有数据。NVMe传下来的数据都是放在TLP的数据部分的(Payload)。为实现不同的目的,TLP可分为以下几种类型:
- Configuration Read/Write
- I/O Read/Write
- Memory Read/write
- Message
- Completion
注意,这个Completion跟NVMe层的Completion不是同一个东西,他们处在不同层。在NVMe命令处理过程中,PCIe传输层基本只用Memory read/write TLP来为NVMe服务,其他TLP我们不用管。
一图看懂NVMe命令处理流程

首先,Host准备了一个Read命令给SSD

基本意思就是,这是个读指令,Host需要从起始LBA 0x20E0448(SLBA)上读取128个DWORD (512字节)的数据,读到哪里去呢?PRP1给出内存地址是0x14ACCB000。这个命令放在编号为3的SQ里 (SQID = 3),CQ编号也是3 (CQID = 3)。
第二步就是:Host通过写SQ的Tail DB,通知SSD来取命令。

上图中,上层是NVMe层,下层是PCIe的传输层,这一层我们看到的是TLP。Host想往SQ Tail DB中写入的值是5。PCIe是通过一个Memory Write TLP来实现Host写CQ的Tail DB的。
一个Host,下面可能连接着若干个Endpoint,该SSD只是其中的一个Endpoint而已,那有个问题,Host怎么能准确更新该SSD Controller中的Tail DB寄存器呢?怎么寻址?其实,在上电的过程中,每个Endpoint的内部空间都会通过内存映射(memory map)的方式映射到Host的内存中,SSD Controller当中的寄存器会被映射到Host的内存,当然也包括 Tail DB寄存器。Host在用Memory Write写的时候,Address只需设置该寄存器在Host内存中映射的地址,就能准确写入到该寄存器。以上图为例,该Tail DB寄存器应该映射在Host内存地址F7C11018,所以Host写DB,只需指定这个物理地址,就能准确无误的写入到对应的寄存器中去。应该注意的是:Host并不是往自己内存的那个物理地址写入东西,而是用那个物理地址作为寻址用,往SSD方向写。否则就太神奇了,往自己内存写东西就能改变SSD中的寄存器值,那不是量子效应吗?我们的东西还没有那么玄乎。
第三步:SSD收到通知,去Host端的SQ中取指。

PCIe是通过发一个Memory Read TLP到Host的SQ中取指的。可以看到,PCIe需要往Host内存中读取16个DWORD的数据。为什么是16 DWORD数据,因为每个NVMe命令的大小是64个字节。从上图中,我们可以推断SQ 3当前的Head指向的内存地址是0x101A41100?怎么推断来的?因为SSD总是从Host 的SQ的Head取指的,而上图中,Address就是0x101A41100,所以我们有此推断。
在上图中,SSD往Host发送了一个Memory Read的请求,Host通过Completion的方式把命令数据返回给SSD。和前面的Memory Write不同,Memory Read中是不含数据,只是个请求,数据的传输需要对方发个Completion。像这种需要对方返回状态的TLP请求,我们叫它Non-Posted请求。怎么理解呢?Post,有”邮政”的意思,就像你寄信一样,你往邮箱中一扔,对方能不能收到,就看快递员的素养了,反正你是把信发出去了。像Memory Write这种,就是Posted请求,数据传给对方,至于对方有没有处理,我们不在乎;而像Memory Read这种请求,它就必须是Non-Posted了,因为如果对方不响应(不返回数据)给我,Memory Read就是失败的。所以,每个Memory read请求都有相应的Completion。
第四步:SSD执行读命令,把数据从闪存中读到缓存中,然后把数据传给Host。
数据从闪存中读到缓存中,这个是SSD内部的操作,跟PCIe和NVMe没有任何关系,因此,我们捕捉不到SSD的这个行为。我们在PCIe接口上,我们只能捕捉到SSD把数据传给Host的过程。
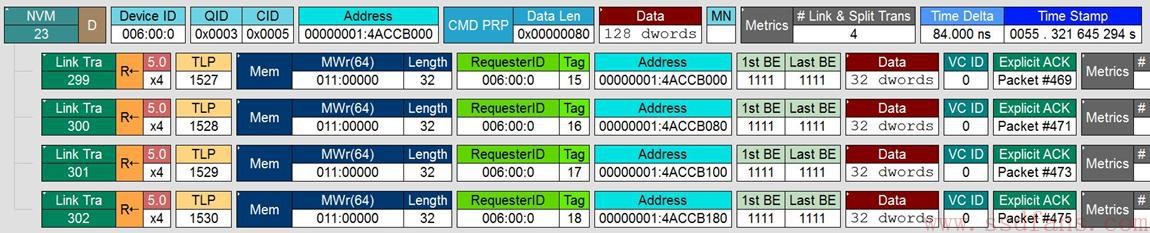
从上图中可以看出,SSD是通过Memory write TLP 把Host命令所需的128个DWORD数据写入到Host命令所要求的内存中去。SSD每次写入32个DWORD,一共写了4次。正如之前所说,我们没有看到Completion,合理。
第五步就是:SSD往Host的CQ中返回状态
SSD一旦把数据返回给Host,SSD认为命令以及处理完毕,

从上图中可以看出,SSD是通过Memory write TLP 把16个字节的命令完成状态信息写入到Host的CQ中。
第六步就是:SSD采用中断的方式告诉Host去处理CQ
SSD往Host的CQ中写入后

SSD中断Host,NVMe/PCIe有四种方式:Pin-based interrupt, single message MSI,multiple message MSI,和MSI-X。关于中断,具体的可以参看spec 第171页,有详细介绍,有兴趣的可以去看看。从上图中,这个例子中使用的是MSI-X中断方式。跟传统的中断不一样,它不是通过硬件引脚的方式,而是把中断信息和正常的数据信息一样,PCIe打包把中断信息告知Host。上图告诉我们,SSD还是通过Memory Write TLP把中断信息告知Host,这个中断信息长度是1DWORD。
第七步就是:Host处理相应的CQ。Host收到中断后,Host处理相应的CQ。这步是在Host端内部发生的事情,在PCIe线上我们捕捉不到这个处理过程。
最后一步,Host处理完相应的CQ后,需要更新SSD端的CQ Head DB,告知SSD CQ处理完毕。

跟前面一样,Host还是通过Memory Write TLP更新SSD端的CQ Head DB。
5.NVMe中端到端数据保护功能
Host与SSD之间,数据传输的最小单元是逻辑块(Logical Block,LB),每个逻辑块大小可以是512/520/1024/2048/4096字节等,Host在格式化SSD的时候,逻辑块大小就确定了,以后两者就按这个逻辑块大小进行数据交互。
数据从Host到NVM(Non-Volatile Memory,目前一般是闪存,后面我就用闪存来代表NVM),首先要经过PCIe传输到SSD的Controller,然后Controller把数据写入到闪存;反过来,Host想从闪存上读取数据,首先SSD Controller从闪存上获得数据,然后经过PCIe把数据传送给Host。
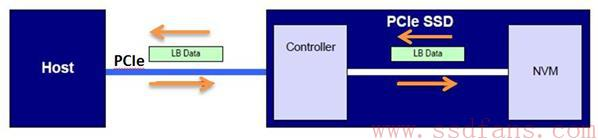
Host与SSD之间,数据在PCIe上传输的时候,由于信道噪声的存在(说白了就是存在干扰),可能导致数据出错;另外,在SSD内部,Controller与闪存之间,数据也可能发生错误。路途凶险。为确保Host与闪存之间数据的完整性,即Host写入到闪存的数据与最初Host写的数据一致,以及Host读到的数据与最初从闪存上读上来的数据一致,NVMe提供了一个端到端数据保护功能。
除了逻辑块数据本身,NVMe还允许每个逻辑块带个助理,叫做元数据(Meta Data)。这个助理的职责,NVMe虽然没有明确的要求,但如果数据需要保护,NVMe要求这个助理必须能充当保镖的角色。
元数据有两种存在方式,一种是作为逻辑块数据的扩展,和逻辑块数据放一起存放,这是贴身保镖:

另外一种方式就是逻辑块数据放在一起,元数据单独放在别处。虽不是贴身保护,但保镖在附近时刻注意着主人的安全,属非贴身保镖:

贴身保护与否,我们不关心形式,我们只关心元数据是如何保护逻辑块数据的。NVMe要求每个逻辑块数据的保镖配备下面这把武器:

其中的”Guard”是16比特的CRC (Cyclic Redundancy Check),它是逻辑块数据算出来的;”Application Tag”和”Reference Tag”包含该数据块的逻辑地址(LBA)等信息。CRC校验能够检测出数据是否有错,后者则是保证数据不会出现张冠李戴的问题。
佩了保镖的数据看起来就是下面这个样子(以512字节的数据块为例):

在Host与SSD数据传输过程中,NVMe可以让每个逻辑块数据都带上保镖,也可以让他们不带保镖,也可以在某个治安差的地方把保镖带上,然后在治安环境好的地方不用保镖。
Host往SSD写入数据,不带保镖的情况:
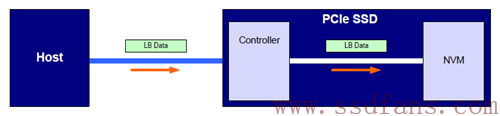
如果是无关紧要的数据,完全没有必要进行端到端的保护,毕竟数据保护需要传输额外的数据 (每个逻辑数据块需要至少额外8字节的数据保护信息,有效带宽减少),还需要SSD做额外的数据完整性校验(耗时,性能变差),最关键的是PCIe通道上,其数据天然就能受到保护。
对每个TLP来说,其中有个Digest域,就是对HDR和Data进行数据保护的,本质就是CRC。这个Digest是可选的。如果使能了Digest,数据在PCIe上传输是毫无风险的,因为有便衣警察保护,在NVMe层完全没有必要进行额外的数据保护。
当然,它不能发现数据张冠李戴的问题。
Host往SSD写入数据,全程带上保镖的情况:
红色PI,Protection Information。
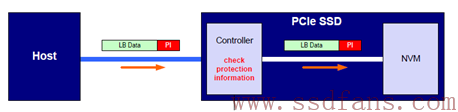
Host数据通过PCIe传输到SSD Controller之间,按理来说数据已经受到PCIe的保护,但PCIe保镖也有可能不在情况,那就是TLP中Digest域可能不存在,这是PCIe允许的。这个时候,如果要保证在PCIe上数据传输的可靠性,就需要NVMe自带保镖。数据到达SSD Controller时,SSD Controller会重新计算逻辑块数据的CRC,与保镖的CRC比较,如果两者匹配,说明数据传输是没有问题的;否则,数据就是有问题的,这个时候,SSD Controller就会给Host报错。
除了CRC校验,还要检测有没有张冠李戴的问题,通过检测Reference Tag 和Application Tag,看看这个没有CRC问题的数据是不是该笔Host写命令对应的数据,如果不匹配,同样需要向Host报错。
如果数据检测没有问题,SSD Controller会把逻辑块数据和PI一同写入闪存中。这个PI一同写入到闪存中有什么意义呢?在读的时候有意义。
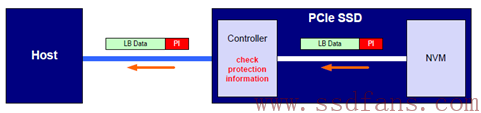
SSD Controller读闪存的时候,会对读上来的数据进行CRC校验,如果写入的时候带有PI,这个时候就能检测出读上来的数据是否正确,从而决定这个数据要不要传给Host。有人要说,对闪存来说,数据不是受ECC保护吗?为什么还要额外进行数据校验?没错,写入到闪存中的数据是受ECC保护,这个没有问题,但在SSD内部,数据从Controller到闪存之间,一般都要经过DRAM或者SRAM,在之前SSD Controller写入到闪存,或者这个时候从闪存读数据到SSD Controller,可能就会发生比特翻转之类的小概率事件,从而导致数据不正确。如果在NVMe层再做个CRC保护,这类数据错误就能被发现了。
除了数据在SSD内发生反转,由于固件问题,或者别的原因,还是会出现数据张冠李戴的问题:数据虽然没有CRC错误,但是它不是我们想要的数据。因此,还需要做Reference Tag和Application Tag检测。
SSD Controller通过PCIe把数据传给Host,Host端也会对数据进行校验,看SSD返回过来的数据是否有错。
Host往SSD写入数据,半程带保镖的情况:
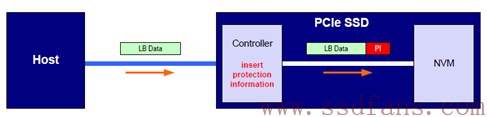
这种情况,Host与Controller端之间是没有数据保护,因为PCIe已经能提供数据完整性保证了(TLP中的Digest使能)。但在SSD内部,Controller到闪存之间,由于乱七八糟的原因(数据反转,LBA数据不匹配),存在数据错误的可能,NVMe要求SSD Controller在把数据写入到闪存前,计算好数据的PI,然后把数据和PI一同写入到闪存。
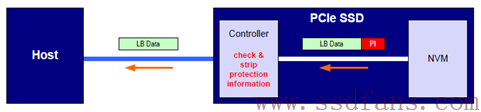
SSD Controller读闪存的时候,会对读上来的数据进行PI校验,如果没有问题,剥除PI,然后把逻辑块数据返回给Host;如果校验失败,说明数据存在问题,SSD需要向Host报错。如下图所示:
数据端到端保护是NVMe的一个特色,其本质就是在数据块当中加入CRC和数据块对应的LBA等冗余信息,SSD Controller或者Host端利用这个这些信息进行数据校验,然后根据校验结果执行相应的操作。加入这些检错信息的好处是能让Host与SSD Controller及时发现数据错误,副作用就是:
- 每个数据块需要额外的至少8字节的数据保护信息,有效带宽减少:数据块大小越小,带宽影响越大。
- SSD Controller需要做数据校验,影响性能。
6.NVMe的命名空间
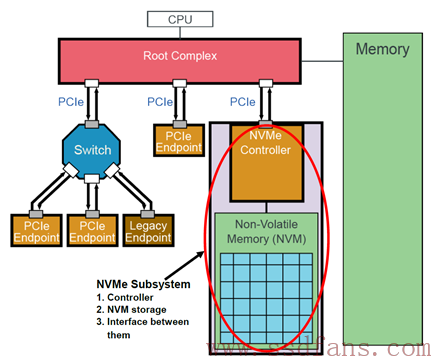
上图中红圈圈起来的是一个NVMe子系统,通常来说就是SSD。一个NVMe SSD主要由SSD Controller,闪存空间和PCIe接口组成。如果把闪存空间划分成若干个独立的逻辑空间,每个空间逻辑块地址(LBA)范围是0到N-1 (N是逻辑空间大小),这样划分出来的每一个逻辑空间我们就叫做NS。对SATA SSD来说,一个闪存空间只对应着一个逻辑空间,与之不同的是,NVMe SSD可以是一个闪存空间对应多个逻辑空间。
每个NS都有一个名称与ID,如同每个人都有名字和身份证号码,ID是独一无二的,系统就是通过 NS的ID来区分不同的NS。
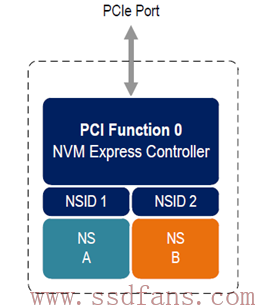
如上图例子,整个闪存空间划分成2个NS,名字分别是NS A和NS B,对应的NS ID分别是1和2。如果NS A大小是M (以逻辑块大小为单位),NS B大小是N,则他们的逻辑地址空间分别是0到M-1和0到N-1。Host读写SSD,都是要在命令中指定读写的是哪个NS中的逻辑块。原因很简单,如果不指定NS,对同一个LBA来说,假设就是LBA 0,SSD根本就不知道去读或者写哪里,因为有两个逻辑空间,每个逻辑空间都有LBA 0。
一个NVMe命令一共64字节,其中第4到第7个Byte指定了要访问的NS。
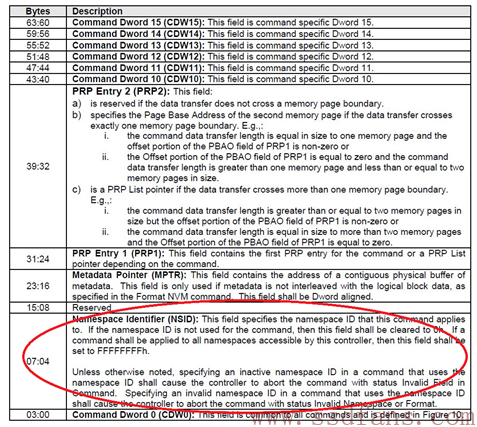
对每个NS来说,都有一个4KB大小的数据结构来描述它
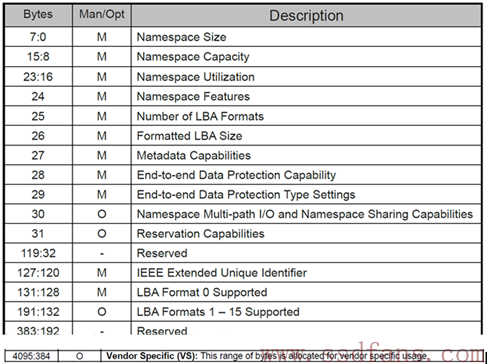
该数据结构描述了该NS的大小,整个空间已经写了多少,每个LBA的大小,以及端到端数据保护相关设置,该NS是否属于某个Controller还是几个Controller可以共享,等等。
NS由Host创建和管理,每个创建好的NS,从Host操作系统角度看来,就是一个独立的磁盘,用户可在每个NS做分区等操作。
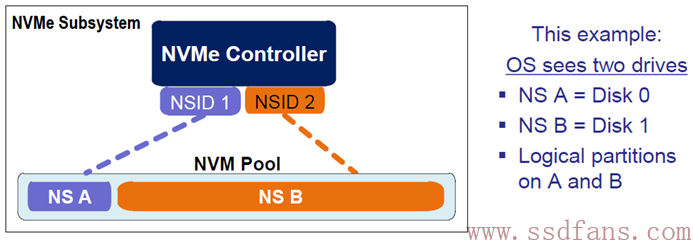
上例中,整个闪存空间划分成两个NS,NS A和NS B,操作系统看到两个完全独立的磁盘。我的天呀,太神奇了,我买一个SSD,居然得到两个磁盘,赚大发了。
每个NS是独立的,逻辑块大小可以不同,端到端数据保护配置也可以不同:你可以让一个NS使用保镖,另一个NS不使用保镖,再一个NS半程使用保镖(见《蛋蛋读NVMe之五》)。
其实,NS更多的是应用在企业级,可以根据客户不同需求创建不同特征的NS,也就是在一个SSD上创建出若干个不同功能特征的磁盘(NS)供不同客户使用。
NS的另外一个重要使用场合是:SR-IOV。
什么是SR-IOV? 英文全称为 Single Root- I/O Virtualization,SR-IOV技术允许在虚拟机之间高效共享PCIe设备,并且它是在硬件中实现的,可以获得能够与本机性能媲美的I/O 性能。单个I/O 资源(单个SSD)可由许多虚拟机共享。共享的设备将提供专用的资源,并且还使用共享的通用资源。这样,每个虚拟机都可访问唯一的资源。
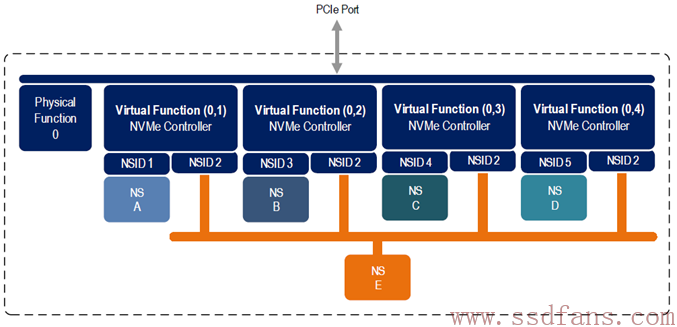
如上图所示,该SSD作为PCIe的一个Endpoint,实现了一个物理功能 (Physical Function ,PF),有4个虚拟功能(Virtual Function,VF)关联该PF。每个VF,都有自己独享的NS,还有公共的NS (NS E)。此功能使得虚拟功能可以共享物理设备,并在没有 CPU 和虚拟机管理程序软件开销的情况下执行 I/O。关于SR-IOV更多知识,请自行百度或者谷歌。这里我们只需知道NVMe中的NS有用武之地就可以。
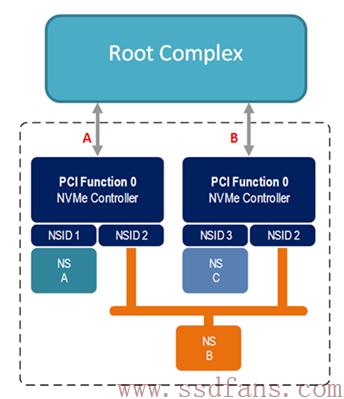
对一个NVMe子系统来说,除了包含若干个NS,还可以由若干个 SSD Controller。注意,这里不是说一个SSD Controller有多个CPU,而是说一个SSD有几个实现了NVMe功能的Controller。
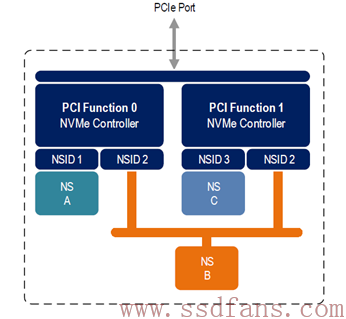
如上图例子,一个NVMe子系统包含了两个Controller,分别实现不同功能(也可以是相同功能)。整个闪存空间分成3个NS,其中NS A由Controller 0(左边)独享,NS C由Controller 1(右边)独享,而NS B是两者共享。独享的意思是说只有与之关联的Controller才能访问该NS,别的Controller是不能对之访问的,上图中Controller 0是不能对NS C进行读写操作的,同样,Controller 1也不能访问 NS A;共享的意思是说,该NS(这里是NS B)是可以被两个Controller共同 访问的。对共享NS,由于几个Controller都可以对它进行访问,所以要求每个Controller对该NS的访问都是原子操作,从而避免同步问题。
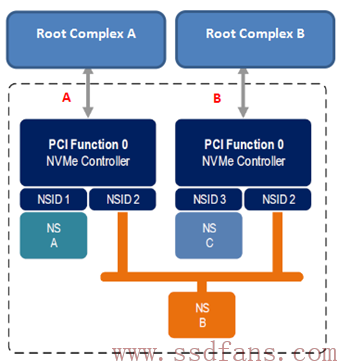
事实上,一个NVMe子系统,除了可以有若干个NS,除了可以有若干个Controller,还可以有若干个PCIe接口。
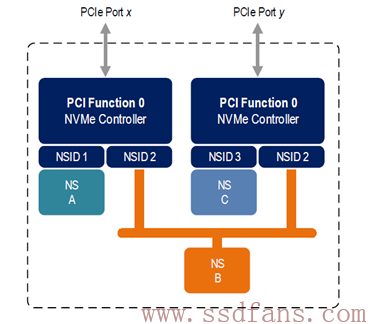
与前面的架构不一样,上图的架构是每一个Controller有自己的PCIe接口,而不是两者共享一个。Dual Port,哈哈,在SATA SSD上没有见过吧。这两个接口,往上有可能连着同一个主机,也可能连着不同的主机。现在能提供 Dual PCIe Port的SSD 接口只有SFF-8639 ,也叫U.2,它支持标准的NVMe协议和Dual-Port,号称SSD接口明日之星。
下图是两个PCIe接口连着一个主机的情况:
为什么要这么玩?
我认为,一方面,Host访问SSD,可以双管齐下,性能可能更好点。不过对访问NS B来说,同一时刻只能被一个Controller访问,双管齐下又如何。考虑到还可以同时操作NS A 和 NS C,性能或多或少的有所提升。
我觉得,更重要的是,这种双接口冗余设计,可以提升系统可靠性。假设 PCIe A接口出现问题,这个时候Host可以通过 PCIe B无缝衔接,继续对NS B进行访问。当然了,NS A是无法访问了。
如果Host突然死机怎么办?据小道消息,阿法狗输给李世石那盘,就是阿法狗死机了,然后重启再战,结果超时认输。哈哈,开个玩笑。在一些很苛刻的场景下,是不允许Host宕机的。但是,是电脑总有死机的时候,怎么办?最直接有效的办法还是采用冗余容错策略:SSD有两个Controller,有两个PCIe接口,那么我主机也弄个双主机:一个主机挂了,另一个主机接管任务,继续执行,你就慢慢重启吧。
蛋蛋似乎就更新了六部分。